多クラス分類BERTを利用した事前学習モデルのファインチューニングTips
BERTを利用したテキスト多クラス分類モデルのファインチューニングについてTipsを紹介します。
目次
参考サイト
今回以下の英語サイトを参考にしました。
環境
Google Colabratoryです。
目的
BERTで用意されている事前学習モデルをファインチューニング(転移学習に近い)し、与えられるテストデータに対してより分類精度の高いモデルの作成を目指します。
ライブラリのインストール&インポート
参考サイト同様に実行します。

データ&モデルのロード
モデルをロードする前にどのモデルをロードするかをパラメータで指定してあげます。

トークナイザーをロードします。トークナイザーは訓練用のテキストデータに対し、トークン化(テキスト情報をベクトル化)するためのものです。

データをロードします。参考サイトではライブラリを利用して訓練データ・検証データ・訓練データラベル・検証データラベル・ターゲット名リスト(targetnames)を用意しています。モデルを学習させるためのデータを使用する際はどんなデータがINPUTになるかを確認することは必須ですのでデータを個別に確認していきましょう。

train_texts, valid_textsは各要素に文章を格納するリストである必要があります。
データの中身は下記のようなイメージです。
['I have a pen', 'I have an apple', 'Oh, APPLEPEN!']
train_labels, valid_labelsは元々がテキストラベルを数値にカテゴライズした数値ラベルが要素として格納されているリストである必要があります。
データの中身は下記のようなイメージです。
[1,0,2]
target_namesは最後にモデルの推論で出力した数値ラベルをテキストラベルに変換する際に利用しますので、数値ラベル昇順で概要するテキストラベルが要素として格納されたリストである必要があります。
例えば、['apple','orange','banana']というtrain_textsがあり、train_labelsは[1,0,2]となっていたとします。学習したモデルに推論させた時に出力が1と出た時、テキストとして'apple'を返したいので['orange','apple','banana']となっているtarget_namesリストを利用することで要素1を指定したときにtarget_namesから'apple'を取り出すことができます。
テキストデータはこのままでは学習に使えないので先ほど作成したトークナイザーで数値ベクトルにトークン化します。

この後のモデルのチューニングではpytorchというフレームワークを利用するため、pytorch用のデータセットにデータを変換してあげる必要があります。
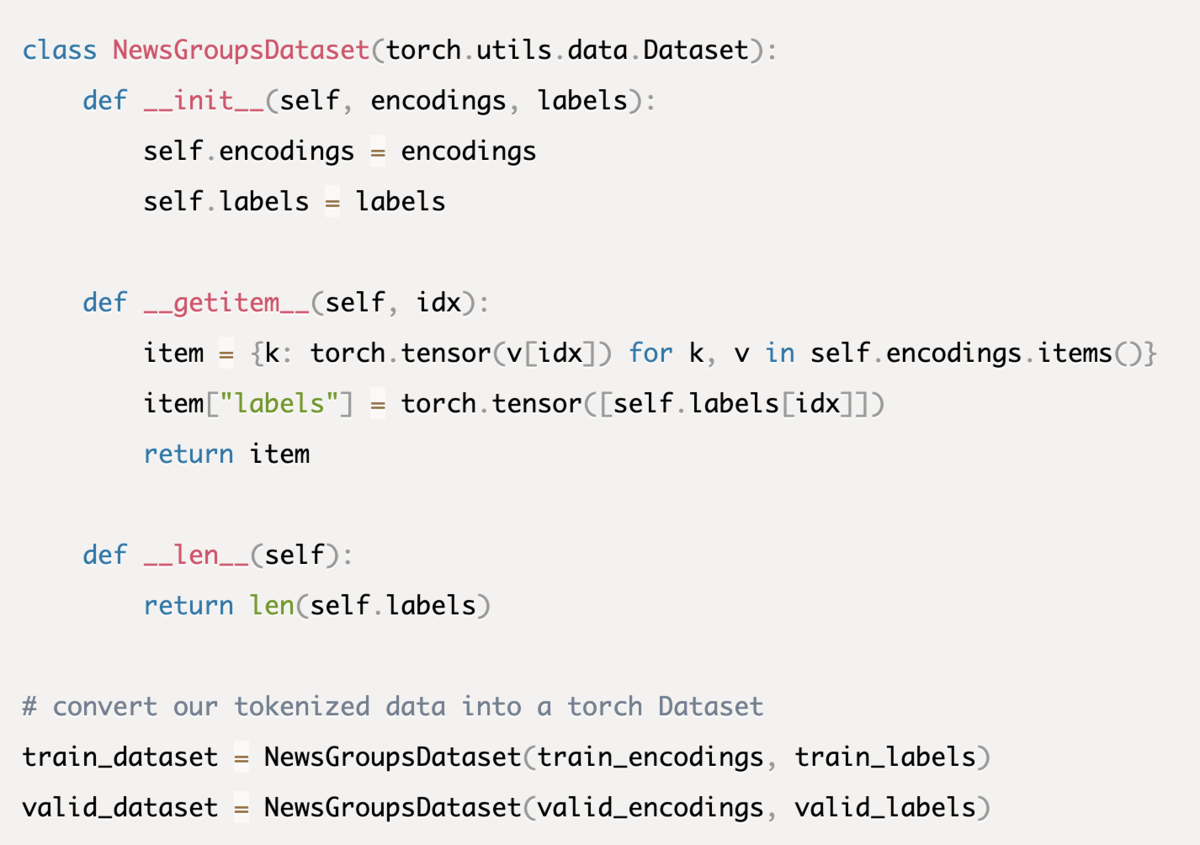
モデルのファインチューニング(トレーニング)
事前学習モデルをダウンロードします。

ここでパラメーターとして最初に指定したmodel_nameと作成したtarget_namesを挿入します。
モデルの学習で使用する評価指標のCall Back関数を設定します。

トレーニングする前にハイパーパラメータを設定します。
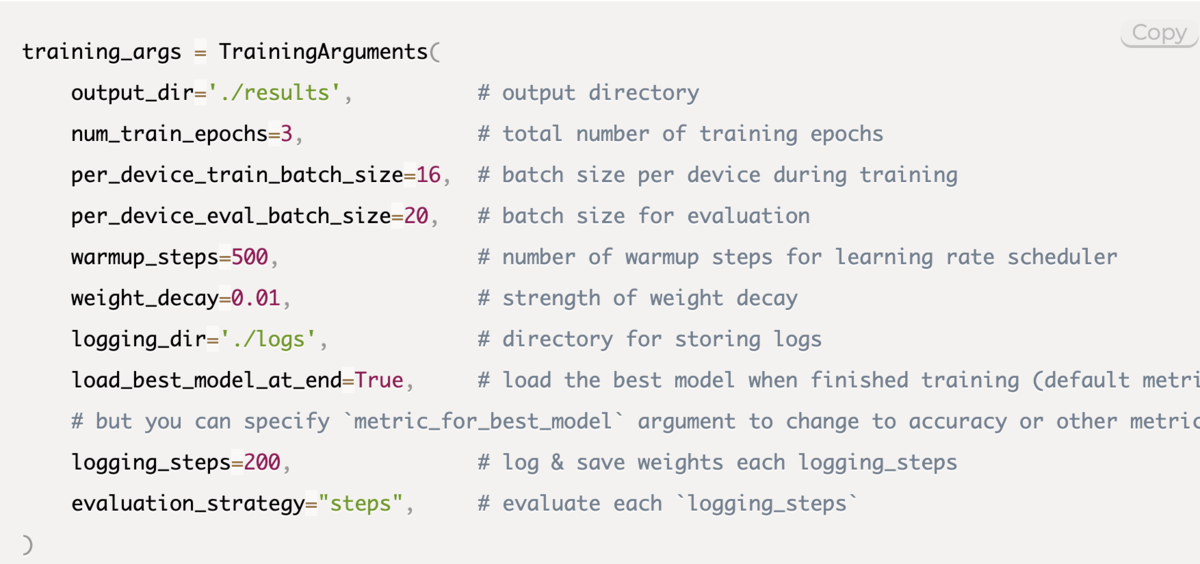

この時にこれまで作成したmodel, args(ハイパーパラメータ),dataset,metrics(評価指標)をパラメーターとして挿入します。
モデルを学習(ファインチューニング)します。

google colabで実行中の様子
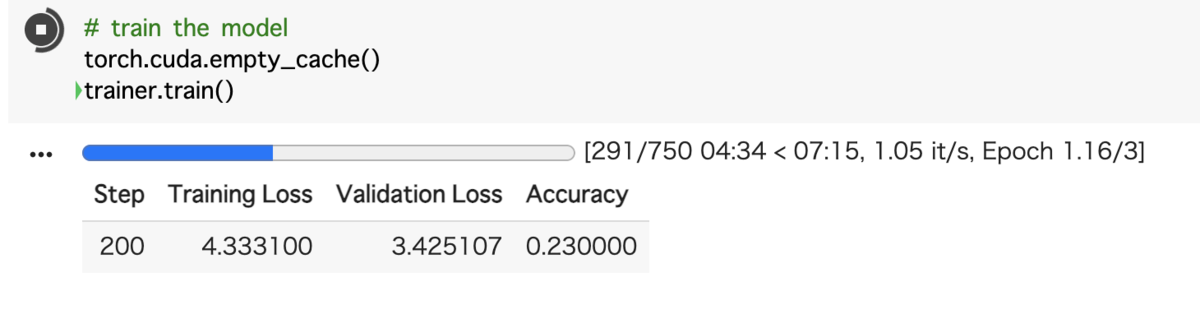
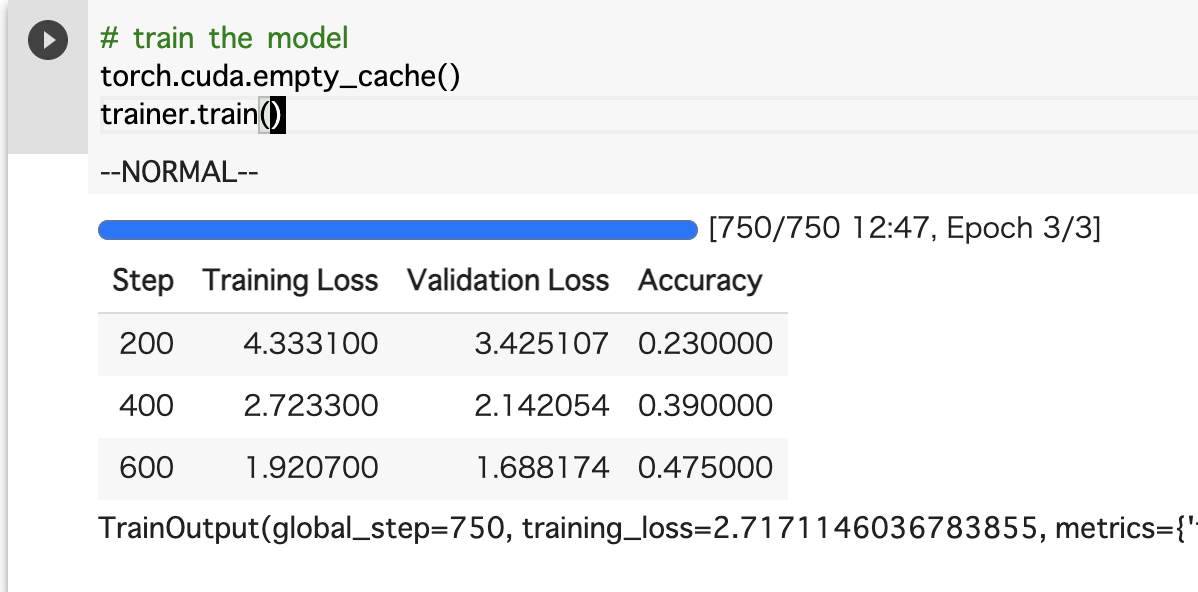
ファインチューニング完了!
Loss(損失関数) が下がっていき、Accuracy(精度)が上がってますね。
学習したモデルを評価してみます。

私の例では以下のようなOutputになりました。まだまだ精度は低いですね。。。笑
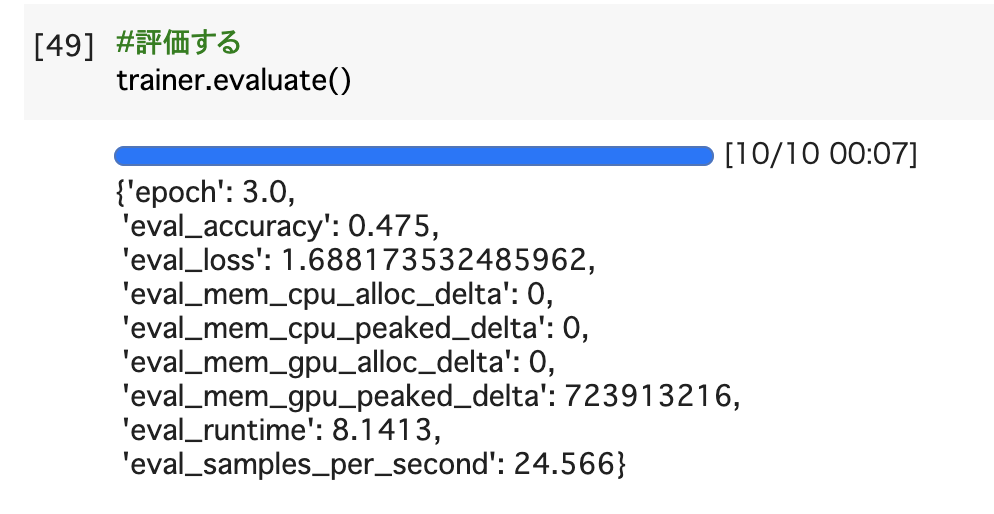
最後にファインチューニングしたモデルを保存しましょう!

次回は推論編を発信しようと思います!
ではまた、会いましょう。